Dùng 1 subagent xử lý 10 task liên tiếp để hoàn thành N file cần xử lý. Ban đầu nhìn rất “tiết kiệm token”, rất hợp lý trên giấy. Nhưng khi chạy thật, dữ liệu bắt đầu nhiễm chéo, output lệch dần giữa các file, và đến lúc khách hàng nhận ra thì mọi thứ đã đi xa hơn mức có thể sửa nhanh.
Vustech đã gặp tình huống này. Và không chỉ một lần.
Bài học đắt giá: đừng bao giờ đánh đổi chất lượng để tiết kiệm token.
Bài toán và giải pháp
Bài toán của chúng tôi: có N file cần xử lý, có system prompt (bao gồm cả hướng dẫn và nhiệm vụ), có yêu cầu đầu ra cụ thể.
Chúng tôi tổ chức để xử lý hàng loạt theo lô (batch processing), sử dụng subagent để giảm context của main session, dễ bao quát:
- Sử dụng Main agent với vai trò điều phối.
- Chia danh sách file theo lô (10 file).
- Khởi tạo các subagent với guideline, trả lại kết quả.
- Main agent kiểm tra và tổng hợp báo cáo từng lô, điều chỉnh cho lô kế tiếp.
- Cứ như vậy, nó làm cho tới hết n file, kết thúc nhiệm vụ.
Giải pháp là vậy nhưng việc chọn cách subagent mới là vấn đề/bài toán chính ở đây cần giải quyết.
Ở đây Vustech ứng dụng single-agent và multi-agent vào trong worker phía dưới gọi là subagent:
Single-agent và multi-agent: vấn đề không nằm ở số lượng
Nghe thì giống bài toán scale hệ thống. Thực ra không phải. Cốt lõi nằm ở cách bạn cô lập ngữ cảnh.
Chúng ta đang đứng giữa hai lựa chọn:
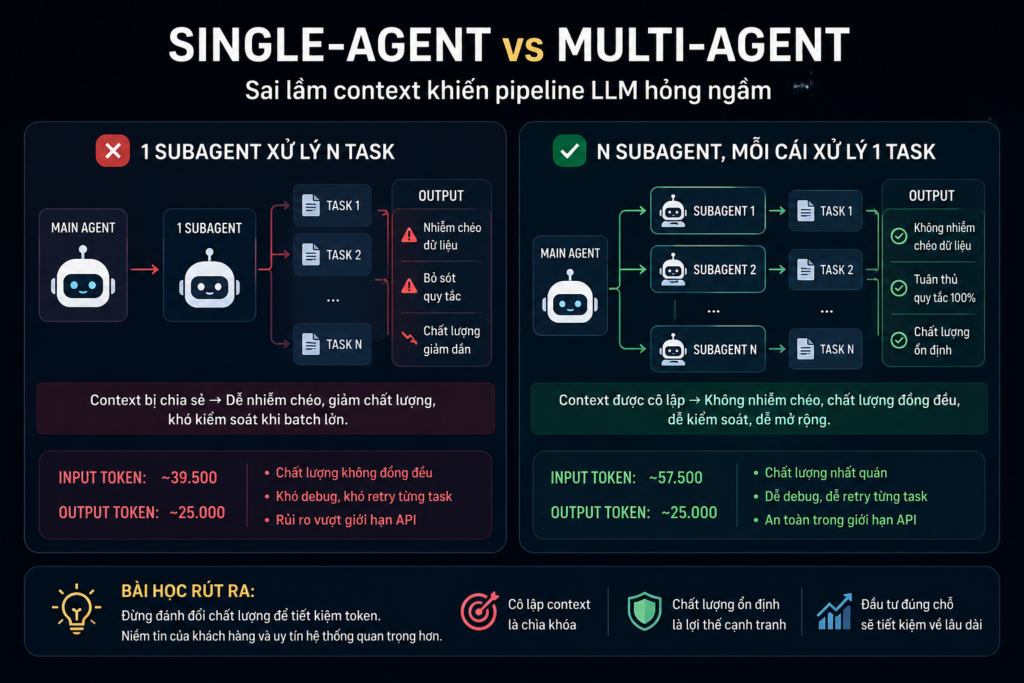
- 1 subagent xử lý N task (shared context, chạy tuần tự)
- N subagent, mỗi cái xử lý 1 task (isolated context, chạy song song)
Thoạt nhìn, phương án đầu tiết kiệm hơn. Ít request hơn, it token hơn.
Nhưng nó mang theo một thứ khó thấy: Context bị “bẩn”, nói cách khác là nhiễu context.
Số liệu thực tế từ Vustech
Case cụ thể khi xử lý batch từng lô:
- 10 file
- ~3.750 token input mỗi file
- ~2.500 token output mỗi file
- ~2.000 token system prompt
Hai cách triển khai:
1 subagent xử lý toàn bộ batch
- Input: ~39.500 token
- Output: ~25.000 token
10 subagent chạy song song
- Input: ~57.500 token
- Output: ~25.000 token
Chênh khoảng 45% input token: không hề nhỏ. NHƯNG chi phí thật không nằm ở đây!!
Reuse context nhiều lần
Điều gì xảy ra khi sử dụng lại context nhiều lần? Nó sẽ không crash? Không exception? Thực tế thì nó chỉ là sai dần. Ha ha!! Đó là sự thật.
Trong dự án của Vustech, các hiện tượng xuất hiện rất rõ nhưng lại khó debug:
- Nội dung file 1 bắt đầu xuất hiện trong file 8 khác.
- Một số yêu cầu nghiệp vụ “biến mất” không lý do
- Từ file thứ 4 trở đi, chất lượng giảm thấy rõ.
Không phải model yếu, không phải prompt tệ. Mà là do context bị kéo dài và trộn lẫn!
Vì sao LLM bắt đầu “đuối” khi batch lớn
Hãy tưởng tượng bạn phải đọc 10 tài liệu khác nhau, mỗi tài liệu có rule riêng, rồi viết lại từng cái thật chính xác mà không được nhầm lẫn. Trong một lần duy nhất!!
Thật là quá khó giữ tập trung. LLM cũng vậy.
Khi context lên gần 40K token – ngưỡng context trung bình của LLMs:
- Sự tập trung (attention) bị phân tán
- Pattern từ các task bắt đầu chồng lên nhau
- Rule không còn được ưu tiên đúng mức.
Không phải nó quên. Nó bị nhiễu.
Multi-agent – lợi thế đến từ sự cô lập
Chúng tôi tiến hành giải pháp chuyển sang mỗi task một subagent:
- Mỗi agent chỉ xử lý ~5.750 token
- Context luôn fresh
- Không carry state giữa các task.
Nghe đơn giản, nhưng hiệu quả rất rõ.
Output giữ được độ ổn định từ đầu đến cuối batch. Không còn hiện tượng “file sau yếu hơn file trước”. Rule được tuân thủ gần như tuyệt đối, kể cả khi logic phức tạp.
Đây không phải tối ưu. Đây là phòng lỗi.
Suy giảm hiệu suất – thứ không hiện trên log
Suy giảm hiệu suất theo thời gian (performance degradation) được thể hiện rõ khi tiến hành cách thứ nhất.
Một pattern lặp lại nhiều lần:
- 1-3 file đầu: rất tốt
- 4-7 file: bắt đầu giảm ~20-30%
- 8-10 file: xuất hiện nội dung sơ sài, lấp chỗ trống, thể hiện sự lười biếng.
Không có error, không có warning, chỉ là chất lượng giảm dần.
Đây thực sự là dạng lỗi nguy hiểm nhất.
Giới hạn API – điểm dễ bị bỏ qua
Phần lớn LLM API hiện nay giới hạn output khoảng 4K-8K token. Trong khi đó, cách tiếp cận single-agent đang yêu cầu ~25K token output trong một request.
Nghe là thấy rủi ro. Nhưng thực tế có thể xảy ra:
- Output bị cắt giữa chừng
- Nội dung trả về thiếu phần quan trọng
- Hoặc tệ hơn, vẫn trả về nhưng không đầy đủ.
Không fail, nhưng không thể sử dụng được (unusable).
Khi nào nên tách subagent
Nên tách single agent/subagent khi không cần phức tạp.
Dùng multi-agent nếu:
- Batch lớn hơn 3 task (ở đây là file)
- Task độc lập
- Rule nghiệp vụ nhiều hoặc khó
- Output cần đồng nhất.
Đừng tiếc token ở đây.
Khi nào giữ 1 subagent là hợp lý
Giữ 1 subagent khi vẫn có chỗ dùng. Nhưng phải đúng ngữ cảnh:
- Task phụ thuộc nhau (pipeline thật sự)
- Cần lý luận tái sử dụng (reuse reasoning): từ phác thảo (outline) chuyển sang mở rộng (expand).
- Context reuse là chủ đích, không phải side effect
Nếu không rơi vào các trường hợp này, tốt nhất là tách ra.
Những lỗi rất hay gặp
1. Reuse context mà không nhận ra
for (task of tasks) {
agent.run(task)
}
Nhìn sạch sẽ, nhưng thực tế đang tích lũy context ngầm qua từng vòng lặp.
2. Truyền output cũ vào task mới
history.push(previousOutput)
Đây là nguồn gây nhiễm chéo phổ biến nhất.
3. Tối ưu token quá sớm
Giảm số agent, gom batch lại. Rồi mất hàng tuần debug những lỗi không thể tái hiện ổn định. Không đáng.
Pipeline Vustech đang dùng sau khi sửa
Không cầu kỳ, nhưng rõ ràng.
Main Agent (Orchestrator)
-> spawn subagent per task
-> mỗi subagent stateless
-> trả kết quả
-> aggregate
Có thể bổ sung thêm:
- validator agent để check output
- retry từng task riêng lẻ
- cache theo từng đơn vị xử lý.
Quan trọng nhất vẫn là context isolation.
Checklist áp dụng ngay
- Batch > 3 task: tách subagent
- Task độc lập: không reuse context
- Không truyền output cũ sang task mới
- Kiểm tra giới hạn output của API trước khi thiết kế
- Test A/B giữa shared và isolated context
- Log theo từng task, không gom batch
- Chuẩn bị retry từng phần
Và, lời chốt cuối cùng là: Token có thể tối ưu sau, nhưng một pipeline sai từ đầu thì càng tối ưu càng dễ hỏng.
Vustech – Xây dựng hệ thống AI mở rộng thực sự hoạt động trong môi trường production

Biên tập viên
Vustech

